Diffused Heads: Diffusion Models Beat GANs
on Talking-Face Generation
Michał Stypułkowski 1 Konstantinos Vougioukas 2 Sen He Maciej Zięba 3,4 Stavros Petridis 2 Maja Pantic 2
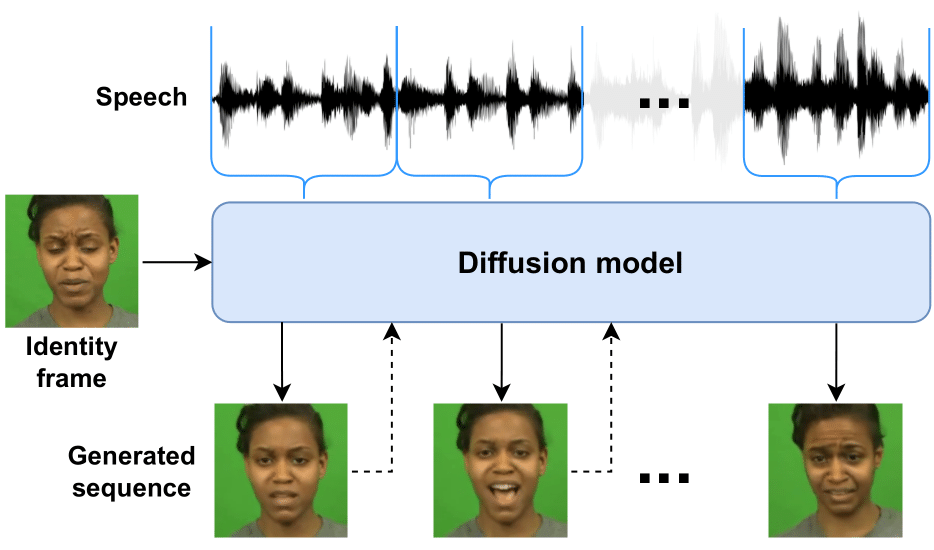
Diffused Heads is the first method successfully using a diffusion model to generate talking faces. Given a single identity frame and an audio clip containing speech, the model samples consecutive frames in an autoregressive manner, preserving the identity, and modeling lip and head movement to match the audio input. Contrary to other methods, no additional guidance is required.
Generated videos
We present generated test samples from CREMA dataset, and generalization results. For more results and supplementary video, please contact us at michal.stypulkowski[at]cs.uni.wroc.pl.
CREMA
Test set examples from CREMA. None of the participants was included in the training set.
Generalization
Results of video generation given inputs from sources not used during the training.
Abstract
Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
Bibtex
@inproceedings{stypulkowski2022diffused,
title = {{Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation}},
author = {Stypu{\l}kowski, Micha{\l} and Vougioukas, Konstantinos and He, Sen and Zi\k{e}ba, Maciej and Petridis, Stavros and Pantic, Maja},
booktitle = {https://arxiv.org/abs/2301.03396},
year = {2023}
}
Acknowledgements
We thank Kacper Kania for the website's template.